ECサイトを運営していて、検索結果に表示したくない、検索結果に表示しない方がよいページもあります。
検索結果への表示(インデックス)をコントロールするにはnoindexメタタグを使用します。
noindexとは何で、Shopifyではどうやって設定するのか、本記事で詳しく解説します。
noindexメタタグとは
noindexメタタグとは、特定のWebページを検索エンジンにインデックスさせないよう指示するためのHTMLタグです。
インデックスとは、Webページが検索エンジンのデータベースに登録されることです。
インデックスされたWebページは検索結果に表示され、インデックスされていないWebページは検索結果には表示されません。
よって、noindexメタタグを記述すれば、検索結果で非表示にするWebページを管理できます。
noindexは、ユーザーにとって必要なページだが検索結果には表示したくない、あるいはSEO上好ましくないページに対して使用し、以下のような場合によく利用されます。
- 検索エンジンからの流入が不要なページ
- 情報量が少ないページや重複コンテンツ
- サイト全体の評価を下げる可能性のある低品質なページ
インデックスをコントロールすることは、SEOの評価にも影響します。
noindexの書き方
<meta name="robots" content="noindex">上記コードをheadタグ内に記述します。
このコードをGoogleなどの検索エンジンロボットが認識すると、検索結果に表示されなくなります。
メタフィールドを使ってnoindexを設定する
Shopifyではnoindexを設定できるメタフィールドが用意されているので、簡単に機能を実装できます。

[設定]→[カスタムデータ]画面から、任意のページタイプを選択します。今回は、例として[ページ]を選択します。

[定義を追加する]をクリック。
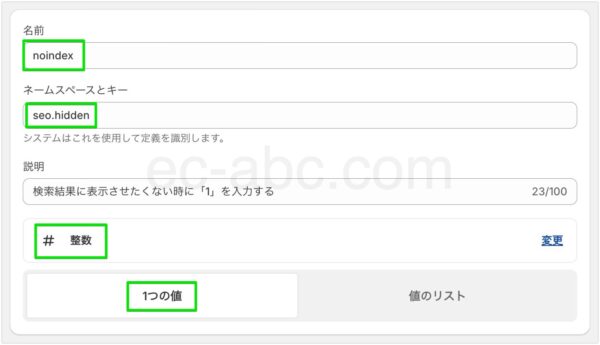
[名前]は自分にとってわかりやすい名前を入力します。今回は[noindex]としました。
[ネームスペースとキー]は[seo.hidden]と入力します。
[説明]は任意で入力します。各ページのメタフィールド設定欄に表示されます。
データタイプは[整数]で[1つの値]のみを選択します。
最後に[保存]します。

管理画面からnoindexを適用したいページの詳細画面に移動し、メタフィールド欄[noindex]に[1]を入力して[保存]します。
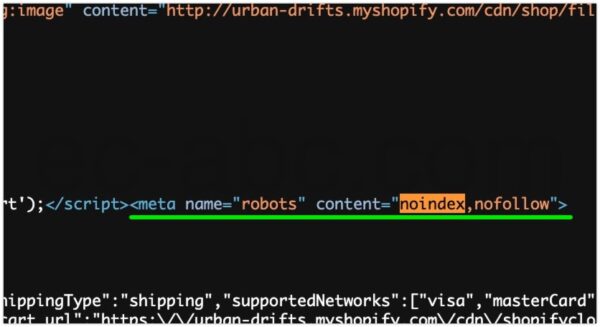
実際のページにアクセスしたら、Webブラウザ上で右クリック(副ボタン)メニューから[(ページの)ソースを表示する]のような文言のメニューを選択します。
ページのソースコードが表示されるので、ブラウザ内検索(Win:Ctrl+f, Mac:⌘+f)してnoindexと検索します。
<meta name="robots" content="noindex,nofollow">の記述が見つかれば正しく設定されています。
nofollowは「リンク先のページを辿らない」という指示です。このままで特に問題ありません。
コードを編集してnoindexを追加する
メタフィールドを使ってnoindexを指定できないページ等は、テーマファイルを編集してnoindexを設定します。
管理画面[オンラインストア]→[テーマ]に移動し、[…]→[コードを編集]をクリックしてコードエディタを開きます。
theme.liquidファイルのheadタグ内に以下のようなコードを記述します。
{% if handle == 'page-handle' %}
<meta name="robots" content="noindex">
{% endif %}page-handleの部分は各ページのハンドルに置換します。
複数のページを指定する場合は以下の様に記述します。
{% if handle == 'handle1' or handle == 'handle2' or handle == 'handle3' %}
<meta name="robots" content="noindex">
{% endif %}noindexを設定できるアプリ
noindexを細かくコントロールしたり効率的に管理したい場合は、アプリを利用するとよいでしょう。
これらのアプリは、noindexの設定と密接に関係するサイトマップの作成も行えます。
特にサイト内のページが増えてきたら、こういったアプリを使うことで効率的に管理できるようになるでしょう。
robots.txtでは検索結果で非表示にできない
検索結果から非表示にする対策として、robots.txtを設定するという情報に出会うかもしれません。
しかしこれは、検索避けの手法としては正しいやり方ではありません。
そもそもrobots.txtは、検索エンジンロボット(クローラー)のアクセスを制御するためのファイルです。
Webサイトの特定のページやディレクトリを記述することで、それらのページにアクセスしないように指示するだけだからです。
つまり、robots.txtは検索インデックスからの削除を命令しているわけではないのです。
robots.txtがnoindexを妨害する
例えば、既にインデックス登録されているWebページを検索で非表示にしたいとします。
noindexメタタグを設定し、さらにrobots.txtにも記述を加え、アクセスを拒否したとします。
この場合、該当のページにはクローラーが来なくなるため、検索エンジンはnoindexが記述されていることにも気付けません。
よって、noindexを指定しているにも関わらず、そのページをクローリングできないため、 検索エンジンはインデックス登録したままの状態となってしまいます。
これがnoindexの代わりにrobots.txtを使うべきではない理由です。
つまり、検索避けをするには、検索エンジンに該当ページにアクセスしてもらった上で、ページのnoindexメタタグを認識してもらう必要があるのです。
それぞれの役割を理解し、適切に使用しましょう。
まとめ
- 検索結果に表示させたくない時はページにnoindexメタタグを指定する
- noindexはheadタグ内に記述する
- Shopifyではnoindexを設定できるメタフィールドが用意されている
- メタフィールドでnoindexを指定したページはsitemap.xmlからも削除される
- 管理画面からメタフィールドでnoindexを指定できないページはコードを編集してカスタマイズする
- noindexの代わりにrobots.txtでクロールを制御するべきではない

コメント
コメント一覧 (2件)
すごい!簡単にできました!
この方法が一番正しいと思いました。
コメントありがとうございます!お役に立ててよかったです!